

详细介绍Java中常用的锁(如ReentrantLock、synchronized、ReadWriteLock等),解析它们的特点、使用场景和实现原理。深入探讨底层代码实现,分析如何通过JVM和Java类库实现线程同步机制,了解锁的公平性、可重入性、死锁及性能影响。
玖拾一
/ Lock
/ c:
/ u:
/ 71 min read
Java 中锁的分类
-
可重入锁,不可重入锁
Java 中提供的 synchronized,ReentrantLock,ReentrantReadWriteLock 都是可重入锁。
重入: 当前线程获取到 A 锁,在获取之后尝试再次获取 A 锁是可以直接拿到的
不可重入: 当前线程获取到 A 锁,在获取之后尝试再次获取 A 锁,无法获取到的,因为 A 锁被当前线程占用着,需要等待自己释放锁再获取锁。
-
乐观锁,悲观锁
Java 中提供的 synchronized,ReentrantLock,ReentrantReadWriteLock 都是悲观锁。
Java 中提供的 CAS 操作,就是乐观锁的一种实现。
悲观锁: 获取不到资源时,会将当前线程挂起(进入 BLOCKED,WAITING),线程挂起会涉及到用户态和内核态的切换,而这种切换是比较消耗资源的。
- 用户态: JVM 可以自行执行的指令,不需要借助操作系统执行。
- 内核态: JVM 不可以自行执行,需要操作系统才可以执行。
乐观锁: 获取不到资源,可以再次让 CPU 调度,重新尝试获取锁资源。
Atomic 原子性类中,就是基于 CAS 乐观锁实现的。
-
公平锁,非公平锁
Java 中提供的 synchronized 只能是非公平锁。
Java 中提供的 ReentrantLock,ReentrantReadWriteLock 可以实现公平锁和非公平锁。
公平锁: 线程 A 获取到了锁资源,线程 B 没有获得,线程 B 去排队,线程 C 来了,锁被 A 持有,同时线程 B 在排队,直接排到 B 的后面,等待 B 拿到锁资源或者 B 取消后,才可以尝试去竞争锁资源。
非公平锁: 线程 A 获取到了锁资源,线程 B 没有获得,线程 B 去排队,线程 C 来了,先尝试竞争一波。
- 拿到锁资源: 开心,插队成功。
- 没有拿到锁资源: 依然要排到 B 的后面,等待 B 拿到锁资源或者 B 取消后,才可以尝试去竞争锁资源。
-
互斥锁,共享锁
Java 中提供的 synchronized,ReentrantLock 是互斥锁。
Java 中提供的 ReentrantReadWriteLock 有互斥锁也有共享锁。
互斥锁: 同一个时间点,只会有一个线程持有者当前互斥锁。
共享锁: 同一个时间点,当前共享锁可以被多个线程同时持有。
ReentrantLock
实现加锁 lock() ----> 线程阻塞:
- wait() 可以阻塞线程,但是必须要结合synchronized 一起使用。
- sleep() 可以阻塞线程,但是必须指定时间,只能通过中断方式唤醒。
- park() 可以阻塞线程,unpark() 进行唤醒。
- while(true) 可以阻塞线程,cas。
公平锁
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
@ReservedStackAccess private boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// state 0 加锁
if (c == 0) {
// hasQueuedPredecessors() 被设计为用于公平的同步器,以避免碰撞
// 如果当前线程之前有一个排队线程,则为true,如果当前线程位于队列的头部或者队列为空,则为false
// compareAndSetState(0, acquires) cas
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 判断加锁线程是否为当前线程 state+1 重入
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
// 加锁失败
return false;
}
}public final boolean hasQueuedPredecessors(){
Node h,s;
if((h=head)!=null){
// (s = h.next) == null 防止空指针的标准写法,除了防止空指针,还会将当前节点复制到h变量上
if((s=h.next)==null||s.waitStatus>0){
s=null; // traverse in case of concurrent cancellation
for(Node p=tail;p!=h&&p!=null;p=p.prev){
if(p.waitStatus<=0)
s=p;
}
}
if(s!=null&&s.thread!=Thread.currentThread())
return true;
}
return false;
}非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
private boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}final boolean nonfairTryAcquire(int acquires){
final Thread current=Thread.currentThread();
int c=getState();
if(c==0){
if(compareAndSetState(0,acquires)){
setExclusiveOwnerThread(current);
return true;
}
}
else if(current==getExclusiveOwnerThread()){
int nextc=c+acquires;
if(nextc< 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}synchronized 在 JDK1.6 的优化
在JDK1.5 的时候 Doug lee 推出了 ReentrantLock,lock 的性能远高于 synchronized,所以 JDK1.6 的时候团队就对 synchronized 进行了大量的优化。
锁消除: 在 synchronized 修饰的代码中,如果不存在操作临界资源的情况,会触发锁消除,你即便写了 synchronized,也不会触发。
public synchronized void method() {
// 没有操作临界资源
// 此时这个方法的 synchronized 可以认为没有
}锁膨胀: 如果在一个循环中,频繁的获取和释放资源,这样带来的消耗很大,锁膨胀就是将锁的范围放大,避免频繁的竞争和获取锁资源带来不必要的消耗。
public void method() {
for(int i = 0, i < 99999;i++) {
synchronized(对象) {
}
}
}
// 这时上面的锁会触发锁膨胀锁升级: ReentrantLock 的实现,是先基于乐观锁的 CAS 尝试获取锁资源,如果拿不到锁资源,才会挂起线程。
synchronized 在 JDK1.6 之前,完全就是获取不到锁,立即挂起当前线程,所以 synchronized 性能很差。
synchronized 就在 JDK1.6 做了锁升级的优化。
- 无锁,匿名偏向: 当前线程没有作为锁的存在。
- 偏向锁: 如果当前锁资源,只有一个线程在频繁的获取和释放,那么这个线程过来,只需要判断,当前指向的线程是否当前线程。
- 如果是,直接拿着锁资源走。
- 如果不是,基于 CAS 的方式,尝试将偏向锁指向当前线程,如果获取不到,触发锁升级,升级为轻量级锁。(偏向锁状态出现了所竞争的情况)
- 轻量级锁: 会采用自旋锁的方式去频繁的以 CAS 的形式获取锁资源(采用的是自适应自旋锁)
- 如果成功获取到,拿着锁资源走。
- 如果自旋了一定的次数,没拿到锁,锁升级。
- 重量级锁: 就是最传统的 synchronized 方式,拿不到锁资源,就挂起当前线程。(用户态&内核态)
synchronized 的实现原理
synchronized 是基于对象实现的。
synchronized 的底层实现是完全依赖JVM虚拟机的,所以先看看对象的存储结构。
对象结构
JVM是虚拟机,是一种标准规范,主要作用就是运行java的类文件的。而虚拟机有很多实现版本,HotSpot就是虚拟机的一种实现,是基于热点代码探测的,有JIT即时编译功能,能提供更高质量的本地代码。HotSpot 虚拟机中对象在内存中可分为对象头(Header),实例数据(Instance Data)和对齐填充(Padding)。其组成结构如下图:
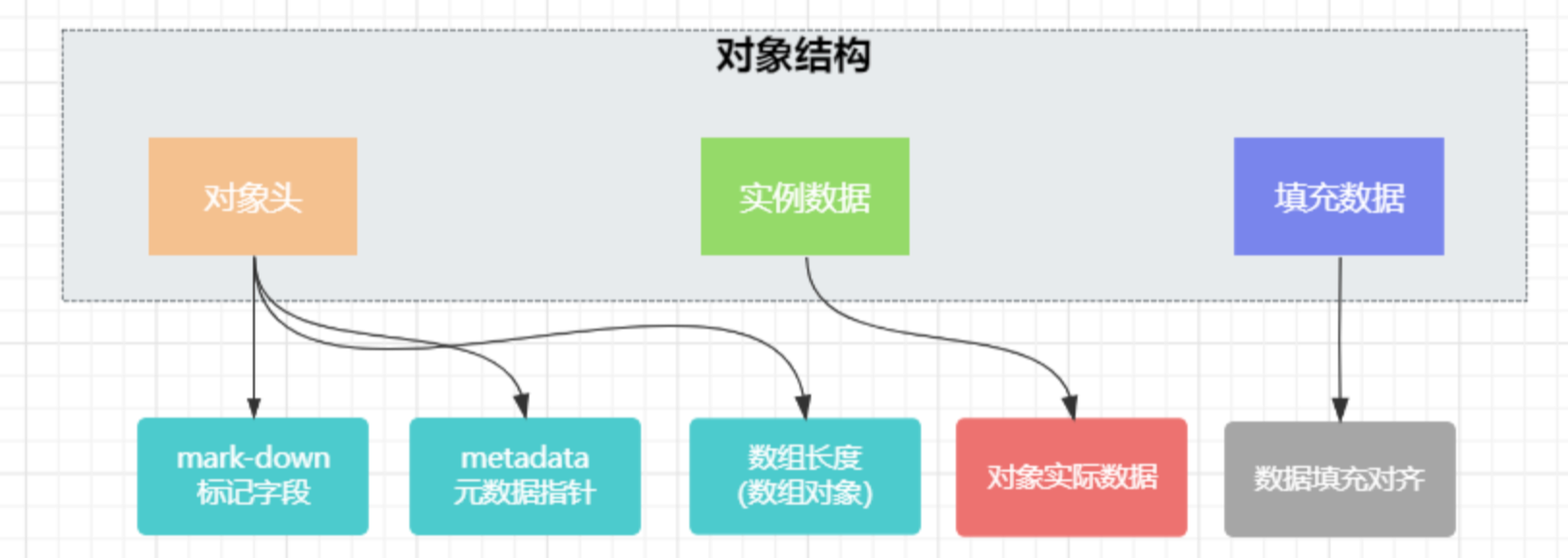
1)实例数据: 存放类的属性数据信息,包括父类的属性信息。如果是数组,那么实例部分还包括数组的长度,这部分内存按4字节对齐。
2)对齐填充: 虚拟机要求对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐。
3)对象头
对于元数据指针,虚拟机通过这个指针来确定这个对象是哪个类的实例;
对于标记字段,用于存储对象自身的运行时数据,其组成如下图
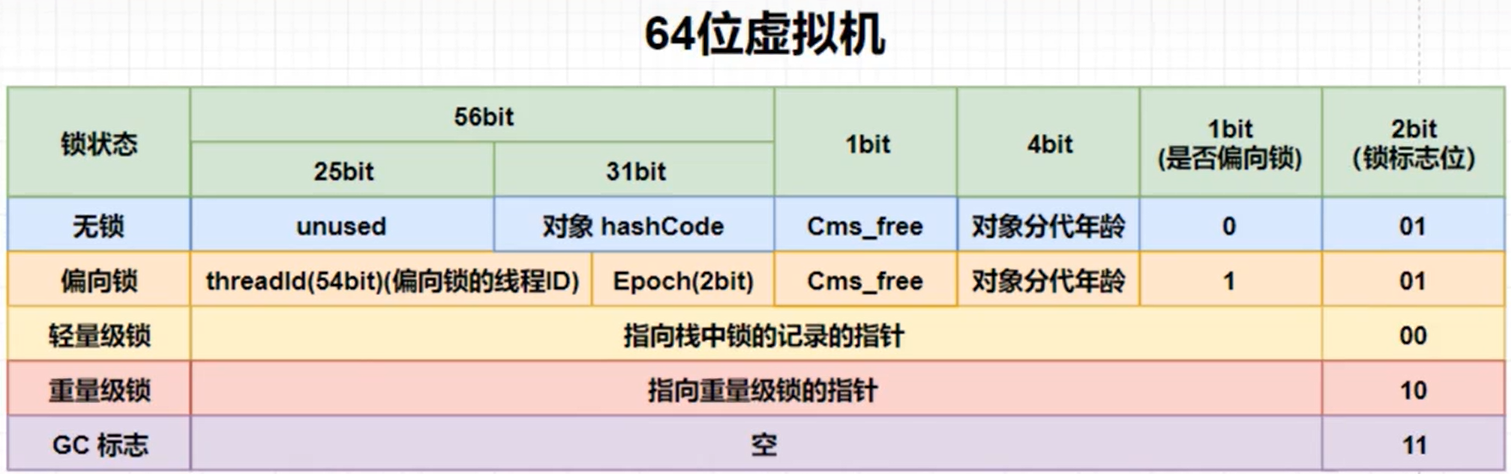
锁信息占3位)在jdk1.6之前只有重量级锁,而1.6后对其进行了优化,就有了偏向锁和轻量级锁。
上锁的原理
JVM规范中描述: 每个对象有一个监视器锁(monitor)。
monitorenter指向同步代码块开始的位置,monitorexit指向同步代码块结束的位置。
当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,执行monitorexit 释放所有权,过程如下:
- 如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
- 如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1。
- 如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象。
这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。
但是监视器锁本质又是依赖于底层的操作系统的互斥锁(Mutex Lock)来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么Synchronized效率低的原因。
因此,这种依赖于操作系统互斥锁(Mutex Lock)所实现的锁我们称之为”重量级锁”。
ReentrantLock和synchronized的区别
在 Java 中,常用的锁有两种: synchronized(内置锁)和 ReentrantLock(可重入锁)。
用法不同
synchronized 可用来修饰普通方法,静态方法和代码块,而 ReentrantLock 只能用在代码块上。
使用 synchronized 修饰代码块:
public void method() {
// 加锁代码
synchronized(this) {
//...
}
}ReentrantLock 在使用之前需要先创建 ReentrantLock 对象,然后使用 lock 方法进行加锁,使用完之后再调用 unlock 方法释放锁,具体使用如下:
public void lockExample() {
private final ReentrantLock lcok = new ReentrantLock();
public void method() {
// lock 加锁操作
lock.lock();
try {
// ...
} finally {
// 释放锁
lock.unlock();
}
}
}获取锁和释放锁方式不同
synchronized 会自动加锁和释放锁,当进入 synchronized 修饰的代码块之后会自动加锁,当离开 synchronized 的代码段之后会自动释放锁,如下图所示:
public class APP {
public void method() {
int count = 0;
synchronized(this) {
for(int i = 0;i < 10;i++) {
count++;
}
}
System.out.println(count);
}
}而 ReentrantLock 需要手动加锁和释放锁,如下图所示:
public void lockExample() {
private final ReentrantLock lcok = new ReentrantLock();
public void method() {
// lock 加锁操作
lock.lock();
try {
// ...
} finally {
// 释放锁
lock.unlock();
}
}
}PS: 在使用 ReentrantLock 时要特别小心,unlock 释放锁的操作一定要放在 finally 中,否者有可能会出现锁一直被占用,从而导致其他线程一直阻塞的问题。
锁类型不同
synchronized 属于非公平锁,而 ReentrantLock 既可以是公平锁也可以是非公平锁。 默认情况下 ReentrantLock 为非公平锁,这点查看源码可知:
public ReentrantLock() {
sync = new NonfairSync();
}使用 new ReentrantLock(true) 可以创建公平锁,查看源码可知:
public ReentrantLock(boolean fair) {
sync = fair ? FairSync() : new NonfairSync();
}响应中断不同
ReentrantLock 可以使用 lockInterruptibly 获取锁并响应中断指令,而 synchronized 不能响应中断,也就是如果发生了死锁,使用 synchronized 会一直等待下去,而使用 ReentrantLock 可以响应中断并释放锁,从而解决死锁的问题,比如以下 ReentrantLock 响应中断的示例:
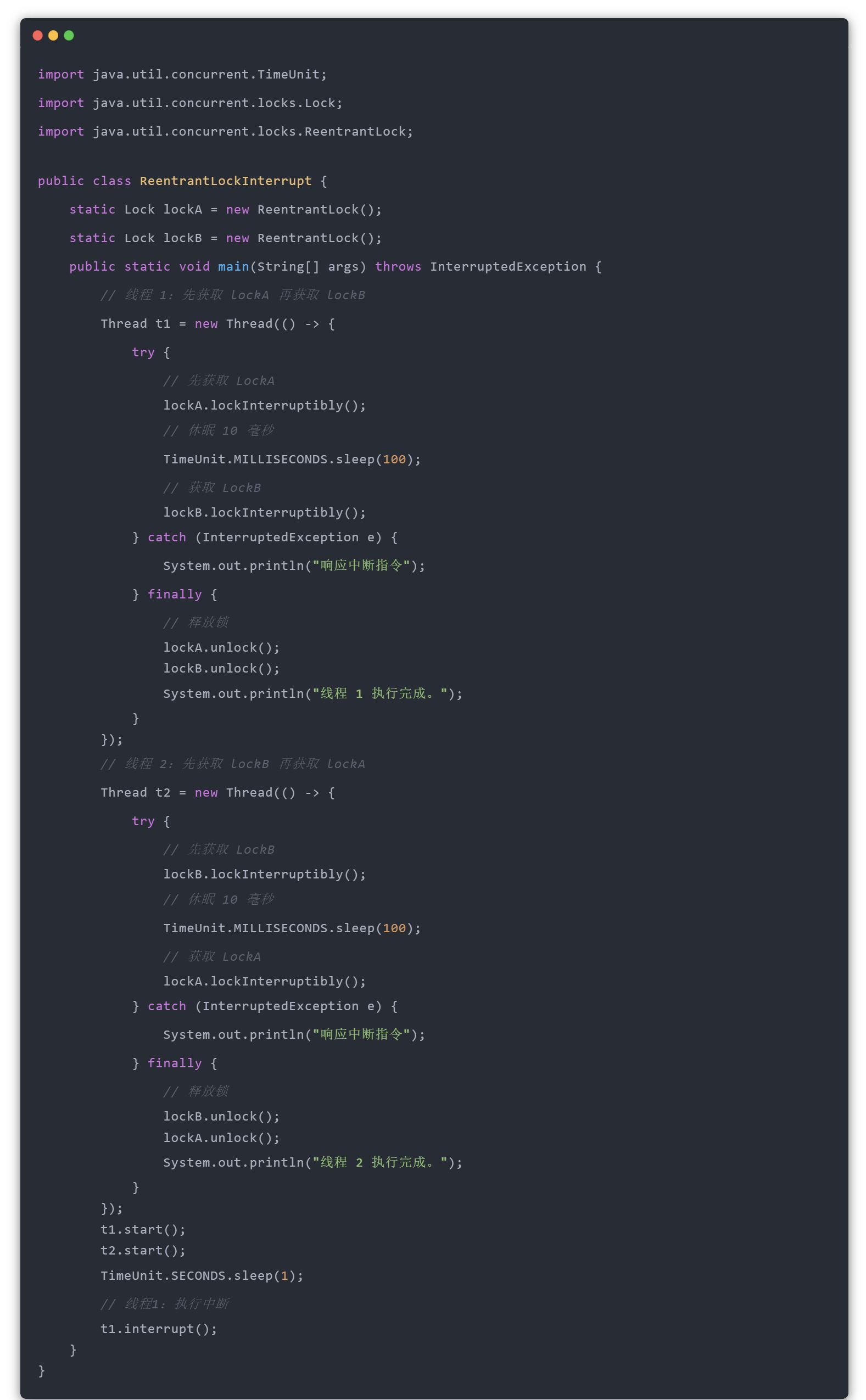
以上程序的执行结果如下所示:
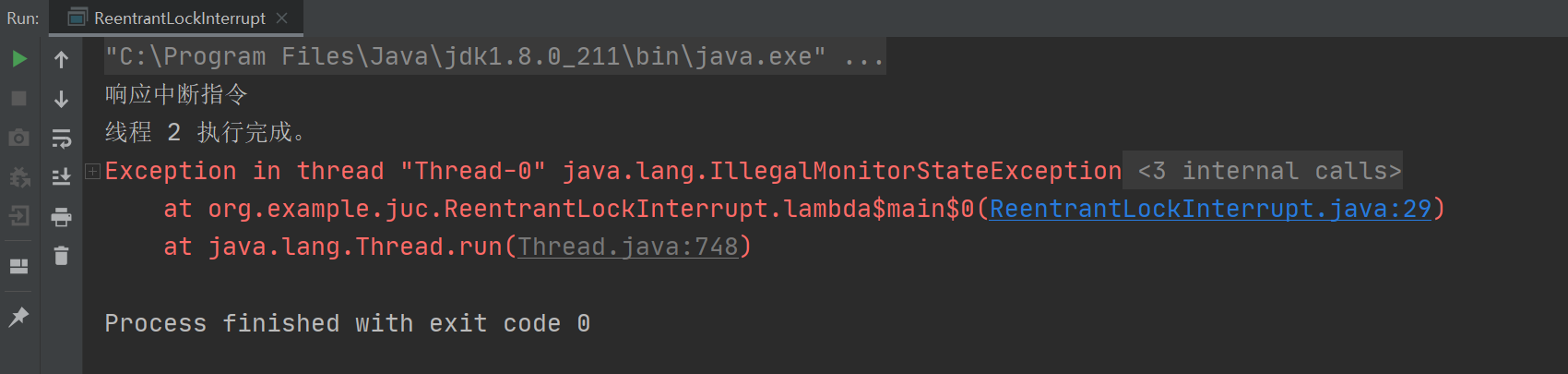
底层实现不同
synchronized 是 JVM 层面通过监视器(Monitor)实现的,而 ReentrantLock 是通过 AQS(AbstractQueuedSynchronizer)程序级别的 API 实现。 synchronized 通过监视器实现,可通过观察编译后的字节码得出结论,如下图所示:
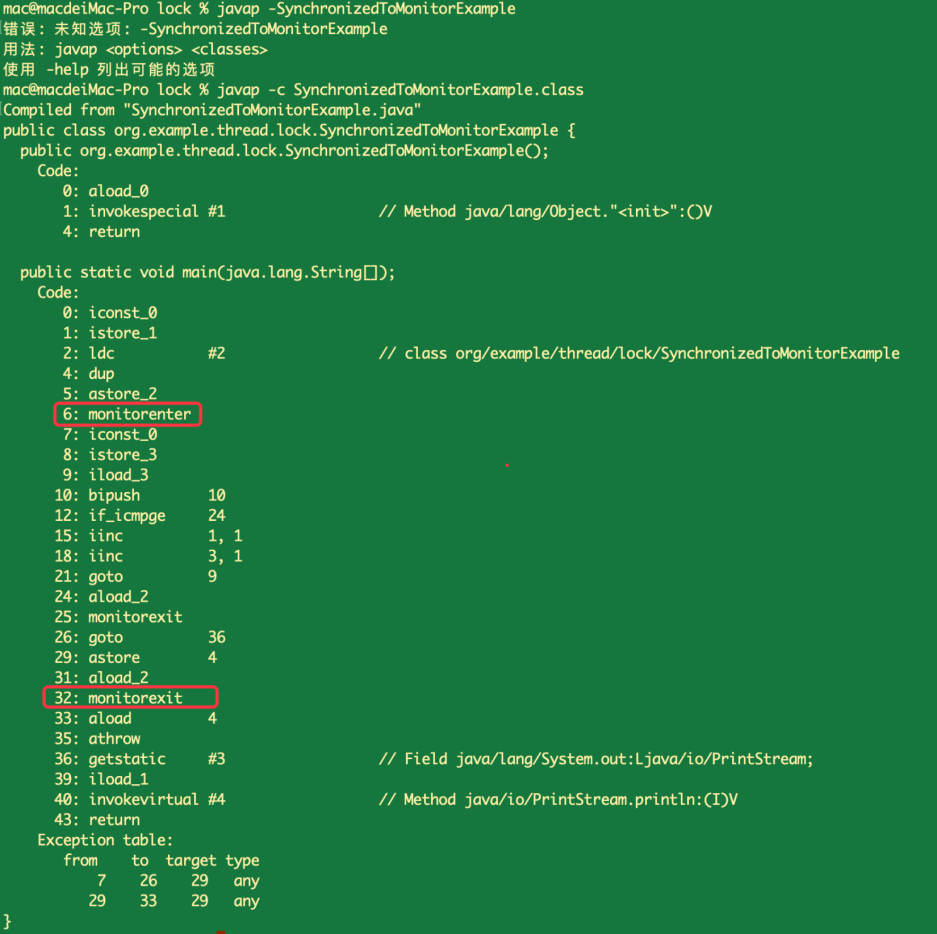
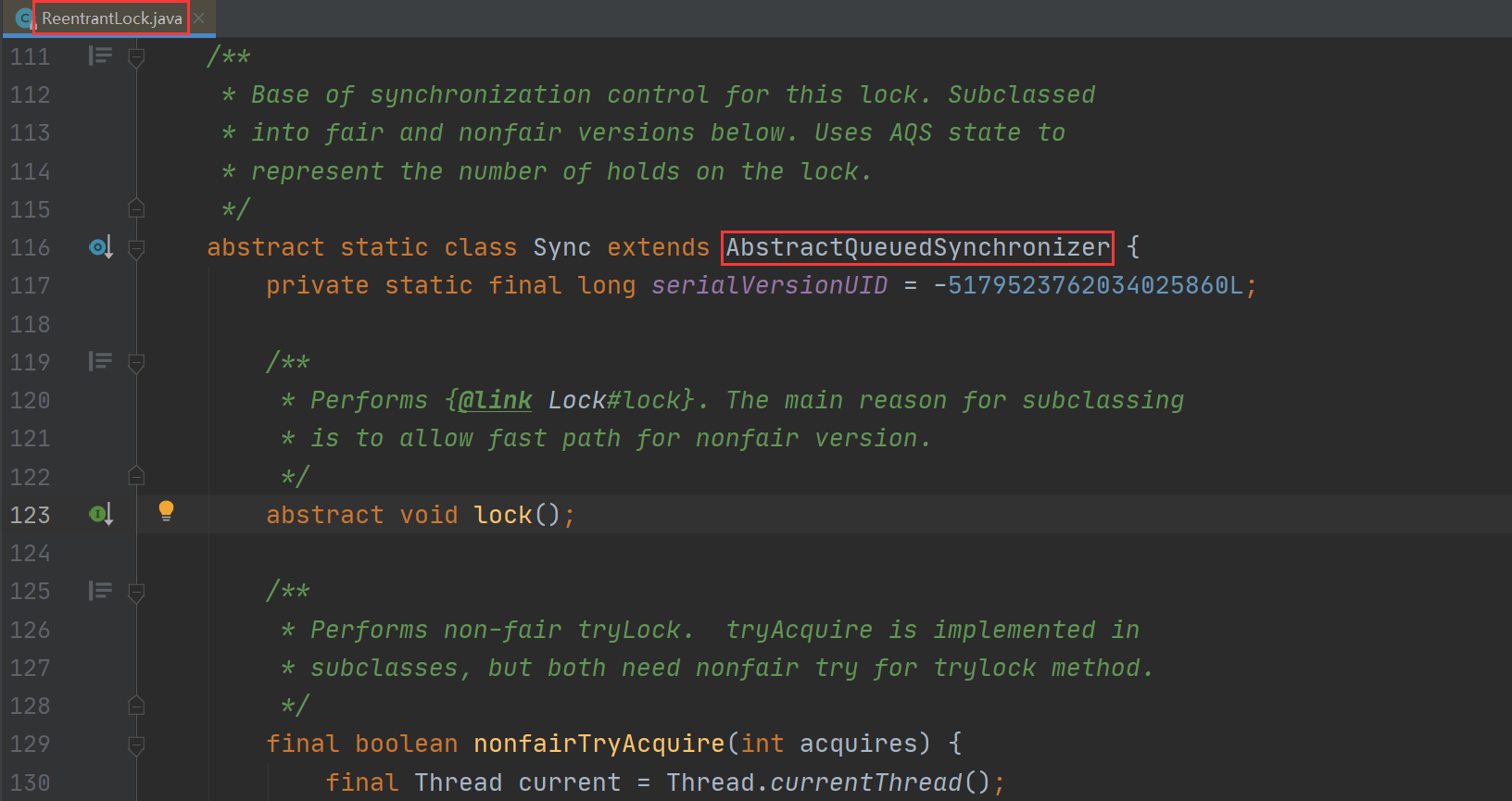
其中 monitorenter 表示进入监视器,相当于加锁操作,而 monitorexit 表示退出监视器,相当于释放锁的操作。 ReentrantLock 是通过 AQS 实现,可通过观察 ReentrantLock 的源码得出结论,核心实现源码如下:
ReentrantReadWriteLock的实现原理
在很多场景下,我们用到的都是互斥锁,线程间相互竞争资源;但是有时候我们的场景会存在读多写少的情况,这个时候如果还是使用互斥锁,就会导致资源的浪费,为什么呢?
因为如果同时都在读的时候,是不需要锁资源的,只有读和写在同时工作的时候才需要锁资源,所以如果直接用互斥锁,肯定会导致资源的浪费。
提供的方法
- readLock(): 获取读锁对象(不是获取锁资源)
- writeLock(): 获取写锁对象(不是获取锁资源)
- getReadLockCount(): 获取当前读锁被获取的次数,包括线程重入的次数
- getReadHoldCount(): 返回当前线程获取读锁的次数
- isWriteLocked(): 判断写锁是否被获取
- getWriteHoldCount(): 返回当前写锁被获取的次数
ReentrantReadWriteLock 还是基于 AQS 实现的,还是对 state 进行操作,拿到锁资源就去干活,如果没有拿到,依然去 AQS 队列中排队。
读锁操作: 基于 state 高 16 位进行操作。
写锁操作: 基于 state 低 16 位进行操作。
ReentrantReadWriteLock 依然是可重入锁。
写锁重入: 读写锁中写锁的重入方式,基本和 ReentrantLock 一致,没有什么区别,依然是对 state + 1 操作即可,只要确认持有锁资源的线程,是当前写锁线程即可,只不过之前 ReentrantLock 的重入次数是 state 的正数取值范围,但是读写锁中写锁范围就小了。
读锁重入: 因为读锁是共享锁,读锁在获取锁资源操作时,是要对 state 的高 16 位进行 +1 操作。因为读锁是共享锁,所以同一时间会有多个读线程持有读锁资源。这样一来,多个读操作在持有读锁时,无法确认每个线程读锁重入的次数。为了去记录读锁重入的次数,每个读操作的线程,都会有一个 ThreadLocal 记录重入的次数。
写锁的饥饿问题: 读锁是共享锁,当有线程持有读锁资源时,再来一个线程想要获取读锁,直接对 state 修改即可。在读锁资源先被占用后,来了一个写锁资源,此时,大量的需要获取读锁的线程请求锁资源,如果可以绕过写锁,直接拿资源,会造成写锁长时间无法获取写锁资源。
锁降级: 当前线程先获取到写锁,然后再获取读锁,再把写锁释放,最后释放读锁。
读锁在拿到锁资源后,如果再有读线程需要获取读锁资源,需要去 AQS 队列排队,如果队列的前面需要获取写锁资源的线程,那么后续读线程是无法拿到锁资源的。持有读锁的线程,只会让写锁线程之前的读线程拿到锁资源。
写锁的获取与释放
获取锁的源码:
protected final boolean tryAcquire(int acquires) {
/*
* Walkthrough:
* 1. If read count nonzero or write count nonzero
* and owner is a different thread, fail.
* 2. If count would saturate, fail. (This can only
* happen if count is already nonzero.)
* 3. Otherwise, this thread is eligible for lock if
* it is either a reentrant acquire or
* queue policy allows it. If so, update state
* and set owner.
*/
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
if (c != 0) {
// (Note: if c != 0 and w == 0 then shared count != 0)
if (w == 0 || current != getExclusiveOwnerThread())
return false;
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// Reentrant acquire
setState(c + acquires);
return true;
}
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires))
return false;
setExclusiveOwnerThread(current);
return true;
}释放锁的源码:
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}读锁的获取与释放
获取锁的源码:
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 &&
getExclusiveOwnerThread() != current)
return -1;
int r = sharedCount(c);
if (!readerShouldBlock() &&
r < MAX_COUNT &&
compareAndSetState(c, c + SHARED_UNIT)) {
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
return fullTryAcquireShared(current);
}释放锁的源码:
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null ||
rh.tid != LockSupport.getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;
if (compareAndSetState(c, nextc))
// Releasing the read lock has no effect on readers,
// but it may allow waiting writers to proceed if
// both read and write locks are now free.
return nextc == 0;
}
}死锁
形成死锁的四个必要条件
- 互斥条件: 进程要求对所分配的资源(如打印机)进行排他性控制,即在一段时间内莫资源仅为一个进程所占有。此时若有其他进程请求资源,则请求进程只能等待。
- 不可剥夺条件: 进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
- 请求与保持条件: 进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己获得的资源保持不放。
- 循环等待条件: 存在一种进程资源的循环等待链,链中每一个进程已获取的资源同时被链中下一个进程所请求。即存在一个处于等待状态的进程集合
{P1,P2,...Pn},其中Pi等待的资源被 P(i+1)占有(i=0,1,…n-1),Pn等待的资源被P0占有。
以上四个条件是死锁的必要条件,只要系统产生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
处理死锁的方法
-
预防死锁
通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或几个条件,来防止死锁的产生。
-
破坏”互斥”条件
就是在系统里取消互斥。若资源不被一个进程独占使用,那么死锁是肯定不会发生的。但一般来说在所列的四个条件中,“互斥”条件是无法破坏的。
-
破坏”占有并等待”条件
破坏”占有并等待”条件,就是在系统中不允许进程在已获得某种资源的情况下,申请其他资源。即要想出一个办法,阻止进程在持有资源的同时申请其他资源:
- 一次申请所需的全部资源,即”一次性分配”。
- 要求每个进程提出新的资源申请前,释放它所占有的资源,即”先释放后申请”。
-
破坏”不可抢占”条件
破坏”不可抢占”条件就是允许对资源实行抢夺:
- 占有某些资源的同时再请求被拒绝,则该进程必须释放已占有的资源,如果有必要,可再次请求这些资源和另外的资源。
- 设置进程优先级,优先级高的可以抢占资源。
-
破坏”循环等待”条件
将系统中的所有资源统一编号,所有进程必须按照资源编号顺序提出申请。
-
-
避免死锁
在资源的动态分配过程中,用某种方法去防止系统进入不安全状态,从而避免死锁的产生。
-
加锁顺序: 线程按照一定的顺序加锁。
-
加锁时限: 线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁。
-
死锁检测: 每当一个线程获得了锁,会在线程和锁相关的数据结构中(map,graph等等)将其记下。除此之外,每当有线程请求锁,也需要记录在这个数据结构中。
-
-
检测死锁
允许系统在运行过程中产生死锁,但可设置检测机构及时检测死锁的发生,并采取适当措施加以清除。
一般来说,由于操作系统有并发,共享以及随机性等特点,通过预防和避免的手段达到排除死锁的目的是很困难的。这需要较大的系统开销,而且不能充分利用资源。为此,一种简便的方法是系统为进程分配资源时,不采取任何限制性措施,但是提供了检测和解脱死锁的手段: 能发现死锁并从死锁状态中恢复出来。因此,在实际的操作系统中往往采用死锁的检测与恢复方法来排除死锁。
-
解除死锁
当检测出死锁后,便采取适当措施将进程从死锁状态中解脱出来。
-
资源剥夺法
挂起某些死锁进程,并抢占它的资源,将这些资源分配给其他的死锁进程。但应防止被挂起的进程长时间得不到资源,而处于资源匮乏的状态。
-
撤销进程法
强制撤销部分,甚至全部死锁进程并剥夺这些进程的资源。撤销的原则可以按进程优先级和撤销进程代价的高低进行。
-
进程回退法
让一(多)个进程回退到足以回避死锁的地步,进程回退时自愿释放资源而不是被剥夺。要求系统保持进程的历史信息,设置还原点。
-
AQS
AQS 就是 AbstractQueuedSynchronized 抽象类,AQS 其实就是 JUC 并发包下的一个基类,JUC 下的很多内容都是基于 AQS 实现了部分功能,比如 ReentrantLock,ThreadPoolExecutor,阻塞队列,CountDownLacth,Semaphore,CyclicBarrier等等都是基于 AQS 实现的。
首先 AQS 中提供了一个由 volatile 修饰,并且采用 CAS 方式修改的 int 类型的 state 变量。
其次 AQS 中维护了一个双向链表,有 head,有 tail,并且每个节点都是 Node 对象。
static final class Node {
static final Node SHARED = new Node();
static final Node EXCLUSIVE = null;
static final int CANCELLED = 1;
static final int SIGEL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
// 上述的状态都存储在 waitStatus
volatile int waitStatus;
volatile Node prev;
volatile Node next;
volatile Thread thread;
}面试须知
AQS 唤醒节点时,为何从后往前找
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;
if (ws < 0)
node.compareAndSetWaitStatus(ws, 0);
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node p = tail; p != node && p != null; p = p.prev)
if (p.waitStatus <= 0)
s = p;
}
if (s != null)
LockSupport.unpark(s.thread);
}在阅读 AQS 源码的过程中,也许会存在这样的困惑,为什么当next指针对应的节点为null 或者取消时,从tail 向前遍历寻找最近的一个非取消的节点。
当前任释放时,需要获取继任者;AQS的实现方式是从tail 向前遍历,之所以这样是与入队时的逻辑有关。
/**
* Inserts node into queue, initializing if necessary. See picture above.
* @param node the node to insert
* @return node's predecessor
*/
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
// 假设线程1执行到这里被挂起,此时 next 指针还没有关联到,后新来的线程 n 可能已经被排列到后面去了,所以当 t 被需要时,它的 next 指针还没有设置或者重置;故需要从后到前寻找,而如果找寻下一个,而这个可能被遗漏了;
// 故api文档中有这样一说 (Or, said differently, the next-links are an optimization so that we don't usually need a backward scan.)
t.next = node;
return t;
}
}
}
}源码内部类Node上的注释中有对这个场景的完整描述:
final boolean isOnSyncQueue(Node node) {
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
if (node.next != null) // If has successor, it must be on queue
return true;
/*
* node.prev can be non-null, but not yet on queue because
* 节点的前置前置节点可能为非空,但是尚未在同步队列中,
* the CAS to place it on queue can fail. So we have to
* 因为cas 入队时可能失败。
* traverse from tail to make sure it actually made it. It
* 所以我们不得不后序遍历以确保正确的发现它。
* will always be near the tail in calls to this method, and
* 它总是在靠近尾节点,当执行这个方法时
* unless the CAS failed (which is unlikely), it will be
* 除非cas 失败(这不太可能),所以我们不会遍历太多
* there, so we hardly evertraverse much.
*/
return findNodeFromTail(node);
}另一方面如果下一个节点时null(已经被GC ),如何找到下一个有效节点,也只能从后往前找了。
ConcurrentHashMap在1.8做了什么优化
JDK1.8 放弃了锁分段的做法,采用CAS和synchronized方式处理并发。以put操作为例,CAS方式确定key的数组下标,synchronized保证链表节点的同步效果。
JDK1.8 ConcurrentHashMap是数组+链表,或者数组+红黑树结构,并发控制使用Synchronized关键字和CAS操作。
-
存储结构的优化
数组+链表 -> 数组+链表+红黑树
-
写数据加锁的优化
-
扩容的优化
协助扩容
-
计数器的优化
LongAddr -> Cell[] 分段和汇总
线程安全,但是复合操作时,只保证弱一致性/最终一致性。
ConcurrentHashMap 的散列算法
当需要向 ConcurrentHashMap 中写入数据时,会根据 key 的 hashcode 来确定当前数据要放在数组的哪一个索引位置上。
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p>The value can be retrieved by calling the {@code get} method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with {@code key}, or
* {@code null} if there was no mapping for {@code key}
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 不允许 key 或者 value 值为 null(HashMap 没有这个限制)
if (key == null || value == null) throw new NullPointerException();
// 根据 key 的 hashcode 计算出一个哈希值,后面得出当前 key-value 要存储在那个数组索引位置
int hash = spread(key.hashCode());
int binCount = 0;
...
}当向 map 中放数据时,用的是 put() 方法,这个方法在 ConcurrentHashMap 的源码实际上是调用了 putVal() 方法。
方法中先对 key 和 value 值进行判空,ConcurrentHashMap 是不允许 key 或者 value 值为 null 的,这也是和 HashMap 的一个区别,然后开始计算 key 的 hashcode,以获取后面得出当前 key-value 要存储在哪个数组索引位置,而在计算 key 的 hash 值时,调用了一个名为 spread 的方法。
/**
* Spreads (XORs) higher bits of hash to lower and also forces top
* bit to 0. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
// 将哈希值的高位传播(XOR)到低位,并将最高位强制为0。 因为表使用了2次方掩码,仅在当前掩码以上的位数不同的一组哈希值总是会发生碰撞。(已知的例子包括在小表中持有连续整数的Float键的集合)。因此,我们应用一个转换,将高位的影响向下分散。在速度,实用性和位传播的质量之间有一个权衡。因为许多常见的哈希集已经是合理分布的(所以不受益于传播),而且因为我们使用树来处理大集的碰撞,我们只是以最便宜的方式XOR一些移位的比特,以减少系统损失,以及纳入最高比特的影响,否则由于表的界限,永远不会被用于索引计算。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}这个方法将 key 的 hashcode 的高低 16 位进行 ”^“(异或)运算,最终又与 HASH_BITS 进行 ”&“(与)运算,此处巧妙的使用了一个转换,通过将 key 的 hashcode 右移 16 位,将其哈希值的高位向下传播到地位,并通过与 HASH_BITS 即0x7fffffff(Integer的最大值,最高位是0,其余都是1)进行的与运算将最高位强制为0。
/*
* Encodings for Node hash fields. See above for explanation.
*/
static final int MOVED = -1; // 代表当前 hash 位置的数据正在扩容
static final int TREEBIN = -2; // 代表当前 hash 位置下挂载的是一个红黑树
static final int RESERVED = -3; // 预留当前索引位置
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash简单来讲就是之前用传统的方式计算 hashcode 时,由于数组长度没那么长,就导致只有低位参与计算,产生哈希冲突的概率较高,将高位与低位进行异或运算可以使得高位也参与到运算中,尽可能的减少哈希冲突,此外附属在哈希值中有特殊含义,因此采用了 spread() 方法中的方式避免生成负的哈希值。
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// n: 数组长度
// i: 当前 Node 要存放的索引位置
// f: 当前数组 i 索引位置上的 Node 对象
// fn: 当前数组 i 索引位置上数据的哈希值
Node<K,V> f; int n, i, fh; K fk; V fv;
// 对是否进行过初始化的处理
// 判断数组是否进行过初始化 如果没有 调用 initTable() 进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 已初始化 基于 i = (n - 1) & hash 计算出当前 Node 需要存储在哪个索引位置
// 通过 tabAt() 方法获取哈希表 i 位置上的数据
// 如果该位置为空 -> 该位置没有数据
// 基于 CAS 方法将数据放在 i 位置上 -> 成功放置后结束循环
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 如果哈希表 i 位置不为空(无法直接放在数组上,产生了哈希冲突)
// 判断当前位置是否在扩容 (fh = f.hash) == MOVED
// 如果等于-1,则说明数组正在进行扩容,会调用 helpTransfer() 方法进行协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// 在不获取锁定的情况下检查第一个节点
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
// 如果不等于-1,则说明未在扩容期间,而且此时此位置下挂的不是一个链表,而是一个红黑树,接下来就是将数据存放到红黑树中的相应位置。
else {
V oldVal = null;
// 针对首个节点进行加锁操作,而不是segment,进一步减少线程冲突
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果在链表中找到值为key的节点e,直接设置e.val =value即可。
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果没有找到值为key的节点,直接新建Node并加入链表即可。
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
// 如果首节点为TreeBin类型,说明为红黑树结构,执行putTreeVal操作。
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
// 如果节点数>=8,那么转换链表结构为红黑树结构。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 计数增加1,有可能触发transfer操作(扩容)。
addCount(1L, binCount);
return null;
}为什么 ConcurrentHashMap 的数组长度需要时 2^n
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}可以看到,在计算当前 Node 具体存放的索引位置时,使用了 n-1,n 代表数组长度,即这个索引位置是通过数组长度-1 与通过 spread() 方法返回的哈希值与运算计算出的,当数组长度为 2^n 时,可以最大程度的避免哈希冲突,因此有这个要求,就算给 ConcurrentHashMap 传入的大小不是 2^n,ConcurrentHashMap 也会计算出大于该数的最小 2^n,赋值给 n。
ConcurrentHashMap 初始化流程
数组是懒加载的,第一次执行put()方法的时候才会进行初始化。
initTable()就是初始化方法,这里面有一个很重要的变量sizeCtl。
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
// 声明标识
Node<K,V>[] tab; int sc;
// 判断有没有初始化,并且完成 tab 的赋值
while ((tab = table) == null || tab.length == 0) {
// 将 sizeCtl 赋值给 sc 变量,判断 sizeCtl 是否小于 0,即是否已经有线程在行始化了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// 可以尝试初始化数组,线程会以 CAS 的方式,将 sizeCtl 改为-1,代表当前线程以始化数组
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
// U.compareAndSetInt(this, SIZECTL, sc, -1) 以 CAS 的方式sizeCtrl的为-1
// 修改成功则开始初始化
try {
// DCL 再次判断当前数组是否已经初始化完成
if ((tab = table) == null || tab.length == 0) {
// 开始初始化
// sizeCtl > 0 就初始化 sizeCtl 长度的数组
// sizeCtl = 0 就初始化默认长度的数组
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 真正初始化操作
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 将 sc 赋值为下一次扩容的阈值
// 如果n=16 n>>>2=4 16-4=12
// 其实就是在当前数组的基础上,增加当前数组长度的 0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}sizeCtl 是数组在初始化和扩容操作时一个控制变量,它的不同值代表不同含义
- ‘>0’: 代表当前数组已经初始化完成,此时 sizeCtl 的值代表当前数组的扩容阈值,或者数组的初始化大小
- 0: 代表当前数组还没初始化
- -1: 代表当前数组正在初始化
- <-1: 低于 16 为代表当前数组正在扩容的线程个数
- 如果是 1 个线程,值就是-2
- 如果是 2 个线程,值就是-3
初始化大致流程:
基于一个while循环,先去判断数组初始化了没有,如果没有,会再次比较sizeCtl的情况,如果正在初始化,则会通过Thread.yield()让出CPU资源,如果没有初始化,则会通过CAS的方式修改sizeCtl的值为-1,修改过后还会再次判断数组是否被初始化了(DCL,以免在当前线程修改sizeCtl的值的时候,已经有别的线程对当前数组完成了初始化),如果当前数组仍然没有被初始化,才会真正开始初始化。
ConcurrentHashMap 扩容流程
主要有三种方式会触发扩容
-
执行 treeifyBin() 方法进行链表转红黑树前,会先尝试通过 tryPresize() 方法进行数组扩容。
当链表长度 > 8 时,会尝试将链表转为红黑树。
/** * Replaces all linked nodes in bin at given index unless table is * too small, in which case resizes instead. */ // 在链表长度大于等于 8 时,尝试将链表转为红黑树 private final void treeifyBin(Node<K,V>[] tab, int index) { Node<K,V> b; int n; // 数组不能为空 if (tab != null) { // 在真正进行链表 -> 红黑树前,会先判断数组长度是否小于MIN_TREEIFY_CAPACITY // MIN_TREEIFY_CAPACITY 即 64 if ((n = tab.length) < MIN_TREEIFY_CAPACITY) // 如果数组长度小于 64,不能将链表转为红黑树,先尝试扩容操作 tryPresize(n << 1); else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { synchronized (b) { if (tabAt(tab, index) == b) { TreeNode<K,V> hd = null, tl = null; for (Node<K,V> e = b; e != null; e = e.next) { TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null); if ((p.prev = tl) == null) hd = p; else tl.next = p; tl = p; } setTabAt(tab, index, new TreeBin<K,V>(hd)); } } } } -
执行 putAll() 方法时,会尝试通过 tryPreSize() 方法对数组进行扩容。
putAll() 方法会传入一个 Map,原先的数组很可能会不够用,因此触发扩容。
/** * Copies all of the mappings from the specified map to this one. * These mappings replace any mappings that this map had for any of the * keys currently in the specified map. * * @param m mappings to be stored in this map */ public void putAll(Map<? extends K, ? extends V> m) { tryPresize(m.size()); for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) putVal(e.getKey(), e.getValue(), false); }向 tryPresize() 中传入需要添加的 Map 的 size。
/** * Tries to presize table to accommodate the given number of elements. * * @param size number of elements (doesn't need to be perfectly accurate) */ // size 是将之前的数组长度,左移一位得到的结果 private final void tryPresize(int size) { // 如果扩容的长度达到了最大值,就使用最大值 // 否则需要保证数组的长度的为 2 的 n 次幂 // 这块的操作是为了初始化操作准备的,因为调用 putAll 方法时,也会触发 tryPresize 方法 // 如果刚刚 new 的ConcurrentHashMap 直接调用了 putAll 方法的话,会通过 tryPresize方法进行初始化 int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1); int sc; while ((sc = sizeCtl) >= 0) { Node<K,V>[] tab = table; int n; // 类似初始化的操作 if (tab == null || (n = tab.length) == 0) { n = (sc > c) ? sc : c; if (U.compareAndSetInt(this, SIZECTL, sc, -1)) { try { if (table == tab) { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; table = nt; sc = n - (n >>> 2); } } finally { sizeCtl = sc; } } } // 越界处理 else if (c <= sc || n >= MAXIMUM_CAPACITY) break; // transfer() 实现扩容操作 else if (tab == table) { // 计算扩容标识戳(用于协助扩容) int rs = resizeStamp(n); // 代表没有线程正在扩容,我是第一个扩容的 if (U.compareAndSetInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)) transfer(tab, null); } } }private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { // n = 数组长度 // stride = 每次线程一次性迁移多少数据到新数组 int n = tab.length, stride; // 基于 CPU 的内核数量来计算,每个线程一次性迁移多少长度的数据最合理 // NCPU = 4 // 数组长度为(1024-512-256-128)/ 4 = 32 // MIN_TRANSFER_STRIDE = 16,为每个线程迁移数据的最小长度 if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range // 第一个进来扩容的线程需要把新数组构建出来 if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") // 将原数组长度左移一位,构建新数组长度 Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // 赋值操作 nextTab = nt; } catch (Throwable ex) { // try to cope with OOME // 到这里,说明已经达到了数组长度的最大取值范围 sizeCtl = Integer.MAX_VALUE; // 设置 sizeCtl 后直接结束 return; } // 将成员变量的新数组赋值 nextTable = nextTab; // 迁移数据时,用到的标识,默认为老数组长度 transferIndex = n; } // 新数组长度 int nextn = nextTab.length; // 在老数组迁移数据后,做的标识 ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); // 迁移数据时,需要用到的标识 // advance: true,代表当前线程需要接收任务,然后再执行迁移,如果为 false,代表已经接收完任务 boolean advance = true; // finishing: false,是否迁移结束 boolean finishing = false; // to ensure sweep before committing nextTab // 循环 i=15 代表当前线程迁移数据的索引值 // bound=0 for (int i = 0, bound = 0;;) { // f = null // fh = 0 Node<K,V> f; int fh; // 当前线程要接收任务 while (advance) { // nextIndex = 16 // nextBound = 16 int nextIndex, nextBound; // 第一次进来,这两个判断肯定进不去 // 对 i 进行--,并且判断当前任务是否处理完毕 if (--i >= bound || finishing) advance = false; // 判断 transferIndex 是否小于等于 0,代表没有任务可领取,结束了 // 在线程领取任务后,会对 transferIndex 进行修改,修改为 transferIndex - stride // 在任务都领取完之后,transferIndex 肯定是小于等于 0 的,代表没有迁移数据的任务可以领取 else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } else if (U.compareAndSetInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { // 对 bound 赋值 bound = nextBound; // 对 i 赋值 i = nextIndex - 1; // 设置 advance 为 false,代表当前线程领取到任务了 advance = false; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; // finishing 为 true 代表扩容结束 if (finishing) { // 将 nextTable 新数组设置为 null nextTable = null; // 将当前数组的引用指向新数组 table = nextTab; // 重新计算扩容阈值 64-16=48 sizeCtl = (n << 1) - (n >>> 1); return; } // 当前线程没有接收到任务,让当前线程结束扩容操作 // 采用 CAS 的方式,将 sizeCtl - 1,代表当前并发扩容的线程数 - 1 if (U.compareAndSetInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // sizeCtl 的高 16 位是基于数组长度计算的扩容戳,低 16 位是当前正在扩容的线程数 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) // 代表当前线程并不是最后一个退出扩容的线程,直接结束当前线程扩容 return; // 如果是最后一个退出扩容的线程,将 finishing和advance 设置位 true finishing = advance = true; // 将 i 设置为老数组长度,让最后一个线程再从尾到头再检查一下,是否数据全部迁移完毕 i = n; // recheck before commit } } else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); else if ((fh = f.hash) == MOVED) advance = true; // already processed else { synchronized (f) { if (tabAt(tab, i) == f) { Node<K,V> ln, hn; if (fh >= 0) { int runBit = fh & n; Node<K,V> lastRun = f; for (Node<K,V> p = f.next; p != null; p = p.next) { int b = p.hash & n; if (b != runBit) { runBit = b; lastRun = p; } } if (runBit == 0) { ln = lastRun; hn = null; } else { hn = lastRun; ln = null; } for (Node<K,V> p = f; p != lastRun; p = p.next) { int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); } setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } else if (f instanceof TreeBin) { TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; for (Node<K,V> e = t.first; e != null; e = e.next) { int h = e.hash; TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); if ((h & n) == 0) { if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; } else { if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; } } ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; setTabAt(nextTab, i, ln); setTabAt(nextTab, i + n, hn); setTabAt(tab, i, fwd); advance = true; } } } } } }首先要确定扩容的大小
/** * The largest possible table capacity. This value must be * exactly 1<<30 to stay within Java array allocation and indexing * bounds for power of two table sizes, and is further required * because the top two bits of 32bit hash fields are used for * control purposes. */ private static final int MAXIMUM_CAPACITY = 1 << 30;大于最大值就取最大值(MAXIMUM_CAPACITY),不是 2^n 就计算大于它且离他最近的 2^n。
/** * Returns a power of two table size for the given desired capacity. * See Hackers Delight, sec 3.2 */ private static final int tableSizeFor(int c) { int n = -1 >>> Integer.numberOfLeadingZeros(c - 1); return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } public static int numberOfLeadingZeros(int i) { // HD, Count leading 0's if (i <= 0) return i == 0 ? 32 : 0; int n = 31; if (i >= 1 << 16) { n -= 16; i >>>= 16; } if (i >= 1 << 8) { n -= 8; i >>>= 8; } if (i >= 1 << 4) { n -= 4; i >>>= 4; } if (i >= 1 << 2) { n -= 2; i >>>= 2; } return n - (i >>> 1); }接着就进入了 while 循环,
-
执行 addCount() 操作时,如果当前元素个数达到了扩容阈值,也会进行扩容。
ConcurrentHashMap 读取数据流程
ConcurrentHashMap 的数据查询都是以 get() 方法为入口的。
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
// tab: 数组,e: 查询指定位置的节点 n: 数组长度
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 基于传入的 key,计算 hash 值
int h = spread(key.hashCode());
// 数组不为 null,数组上得有数据
if ((tab = table) != null && (n = tab.length) > 0 &&
// 查询对应数组的位置上的数据
(e = tabAt(tab, (n - 1) & h)) != null) {
// hash 值一致+key 一致 返回 value
if ((eh = e.hash) == h) {
// key 的==或者 equals 是否一致,如果一致,数组上就是要查询的数据
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash 值<0 (特殊情况,会通过 find() 方法进行 value 的获取)
else if (eh < 0)
// 三种情况: 数组迁移走了,节点位置被占,红黑树
// 如果当前数据已经迁移到新数组 ,调用 ForwardingNode 中的 find()
return (p = e.find(h, key)) != null ? p.val : null;
// 走链表操作
while ((e = e.next) != null) {
// 如果 hash 值一致,并且 key 的==或者 equals 一致,返回当前链表位置的数据
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
// 如果上述三个流程都没有知道指定 key 对应的 value,那就是 key 不存在,返回 null 即可
return null;
}ConcurrentHashMap 计数器的实现
计数器是用来统计 ConcurrentHashMap 的元素个数的,通过 addCount() 方法是吸纳,可以看到 addCount() 方法中有两个重要的对象: CounterCell[] 数组和 baseCount 变量。
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
// b: 原来的 baseCount
// s: 是自增后的元素个数
CounterCell[] cs; long b, s;
// 判断 CounterCell 不为 null,代表之前有冲突问题,有冲突直接进入 if 中
// 如果 CounterCell[] 为 null,直接执行 || 后面的 CAS 操作,直接修改 baseCount
if ((cs = counterCells) != null ||
// 如果对 baseCount++ 成功,直接告辞,如果 CAS 失败,直接进入 if 中
!U.compareAndSetLong(this, BASECOUNT, b = baseCount, s = b + x)) {
// 进入这里,说明有并发问题
// 进入的方式有两种:
// 1.CounterCell[] 有值
// 2.CounterCell[] 无值,但是 CAS 失败
// m: 数组长度 - 1
// c: 当前线程基于随机数,获得到的数组上的某一个 CounterCell
CounterCell c; long v; int m;
// 是否有冲突,默认为 true,代表没有冲突
boolean uncontended = true;
// 判断 CounterCell[] 没有初始化,执行 fullAddCount 方法执行初始化
if (cs == null || (m = cs.length - 1) < 0 ||
// CounterCell[] 已经初始化,基于随机数拿到数组上的一个 CounterCell,如果为 null 执行 fullAddCount
(c = cs[ThreadLocalRandom.getProbe() & m]) == null ||
// CounterCell[] 已经初始化,并且指定索引位置上有 CounterCell
// 直接 CAS 修改指定的 CounterCell 上的 value 即可
// CAS 成功,直接告辞
// CAS 失败,代表有冲突,uncontended = false,执行 fullAddCount 方法
!(uncontended =
U.compareAndSetLong(c, CELLVALUE, v = c.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
// 如果链表长度小于等于 1,不去判断扩容
if (check <= 1)
return;
// 将所有 CounterCell 中记录的数累加,得到最终的元素个数
s = sumCount();
}
// 判断 check 大于等于 0,remove 的操作就是小于 0的,因为添加时,才需要判断是否需要扩容
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// 当前元素个数是否大于扩容阈值,并且数组不为 null,数组长度没有达到最大值
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
// 扩容表示戳
int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;
if (sc < 0) {
// 判断是否可以协助扩容
if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||
(nt = nextTable) == null || transferIndex <= 0)
break;
// 协助扩容
if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 没有线程执行扩容,我来执行扩容
else if (U.compareAndSetInt(this, SIZECTL, sc, rs + 2))
transfer(tab, null);
s = sumCount();
}
}
}他们是记录数据的两个位置:
- 并发量不高时,会通过 baseCount 进行追加
- 并发量较高时,CAS 试图操作 baseCount 失败后,会切换到 CounterCell[] 数组来计数,有多个 CounterCell 可供不同的线程进行选择。
当我们需要获取 ConcurrentHashMap 的元素个数时,会调用 size() 方法。
/**
* {@inheritDoc}
*/
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}而 size() 方法中调用了 sumCount() 方法
final long sumCount() {
CounterCell[] cs = counterCells;
long sum = baseCount;
if (cs != null) {
for (CounterCell c : cs)
if (c != null)
sum += c.value;
}
return sum;
}在 sumCount() 对 baseCount 还有数组 CounterCell[] 中的每个记录进行累加,返回最终值。
CAS 和自旋
自旋
顾名思义,自旋可以理解为”自我旋转”,放到程序中就是”自我循环”,比如 while 循环或者 for 循环。结合着锁来理解的话就是,先获取一次锁,如果获取不到锁,会不停的循环获取,直到获取到。不像普通的锁那样,如果获取不到锁就进入阻塞状态。
CAS
CAS 是什么,compare-and-swap,比较并交换,它是一种思想,一种算法。 CAS 算法有 3 个基本操作数:
- 内存地址 V
- 旧的预期值 A
- 要修改的新值 B
在并发场景下,各个代码的执行顺序不能确定,为了保证并发安全,我们可以使用普通的互斥锁,比如 Java 的 synchronized,ReentrantLock 等。而 CAS 的特点是避免使用互斥锁,当多个线程并发使用 CAS 更新同一个变量时,只有一个可以操作成功,其他都会失败。而且用 CAS 更新失败的线程并不会阻塞,会快速失败并返回一个失败的状态,允许你再次尝试。
而 CAS 是一种原子操作,用于实现多线程环境下的同步和并发控制。 基本原理如下:
- 读取内存值: 首先,CAS 会读取内存中的一个变量的当前值。
- 比较内存值和预期值: 接下来,CAS 会将读取的值与预期值进行比较。如果两者相等,则说明内存中的值没有被其他线程修改。
- 如果相等,则将新值写入内存: 在比较阶段,如果发现内存值与预期值相等,CAS 会尝试将新值写入内存中。这个写入操作是原子的,即在这个过程中不会被其他线程中断。
- 如果写入成功,则操作完成,否则重复上述步骤,如果写入操作成功,CAS 完成。如果写入操作失败,说明在比较和写入的过程中,内存值已经被其他线程修改,此时需要重新执行整个 CAS 操作。
CAS 的基本原理就是利用比较和写入的原子性操作来实现对共享变量的原子操作,从而避免了传统锁机制中的死锁和线程阻塞问题。
自旋锁和 CAS 的关系是什么呢?
其实他们是两个不同的概念,自旋是一种锁优化的机制,在锁优化中自旋锁指线程空转重试获取锁,避免线程上下文切换带来的开销。
CAS 是一种乐观锁机制,CAS 是通过比较并替换,失败的时候可以直接返回 false 不用自旋的获取。只是一般应用场景下,CAS 都会带有重试机制(while 或者 for 实现空转,不断尝试获取)。
如果硬有关系,那么可以这样理解 自旋锁 = 循环 + CAS。
CAS 有哪些缺点呢?
- 自旋等待: CAS 在执行时会进行自旋等待,如果失败则需要重试,这会消耗处理器资源。
- aba 问题: CAS 只能检测到共享变量的值是否发生了变化,但无法检测到变量的值是否经历了类似 a->b->a 的变化,这可能导致一些意外的问题。
- 无法保证公平性: CAS 操作时非阻塞的,因此无法保证等待线程的公平性,可能导致某些线程长时间无法获得执行机会。
- 无法解决死锁: CAS 无法解决死锁问题,如果多个线程同时执行 CAS 操作,可能导致死锁的发生。
- 限制性: CAS 操作通常只能应用于单个变量,对于复杂的数据结构,需要额外的处理来实现原子操作。
总的来说,CAS 虽然具有高效的特点,但也存在着一些局限性和缺点。
什么是 ABA 问题
ABA 问题是在分布式系统中常见的一种数据一致性问题。它的名称来源于三个操作: A(原始值),B(第一个读取),A(第二个读取)。ABA 问题发生在一个线程 T1 读取了一个共享变量的值 A,然后另一个线程 T2 修改了这个共享变量的值为 B,然后又改回 A,最后线程 T1 再次读取这个共享变量的值,发现仍然是 A。在这种情况下,线程 T1 可能会错误地认为共享变量的值没有改变,从而导致数据不一致。
解决 ABA 问题的常见方案是使用版本号或者标记来跟踪数据的变化。通过在每次数据变化时增加版本号或者标记,可以避免 ABA 问题的发生。另外,使用 CAS 操作也可以解决 ABA 问题,CAS 操作会在更新变量时检查变量的值是否仍然是预期值,从而避免了 ABA 问题的发生。
简单的说就是:
比如线程 1 从内存位置 V 中取出 A,辞职线程 2 也取出 A,且线程 2 做了一次 CAS 将值改为了 B,然后又做了一次 CAS 将值改回了 A。此时线程 1 做 CAS 发现内存中还是 A,则线程 1 操作成功。这个时候实际上 A 值已经被其他线程改变过,这与设计思想是不符合的。
那么这个问题出现在哪里呢?
- 如果只在乎结果,ABA 不介意 B 的存在,没什么问题
- 如果 B 的存在会造成影响,需要通过 AtomicStampRefrence,加时间戳解决。