

讲解RocketMQ的核心概念,包括生产者、消费者、主题(Topic)、消息队列和消息存储机制。
玖拾一
/ RocketMQ
/ c:
/ u:
/ 47 min read
一学一个不吱声
RocketMQ 是阿里巴巴在 2012 年开源的消息队列产品,用纯 Java 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,后来捐赠给 Apache 软件基金会,2017 正式毕业,成为 Apache 的顶级项目。RocketMQ 在阿里内部被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,Binglog 分发等场景。经历过多次双十一考验,它的性能,稳定性和可靠性都是值得信赖的。
RocketMQ 有着不错的性能,稳定性和可靠性,具备一个现代的消息队列应该有的几乎全部功能和特性,并且它还在持续的成长中。
RocketMQ 有非常活跃的中文社区,大多数问题可以找到中文的答案。RocketMQ 使用 Java 语言开发,源代码相对比较容易读懂,容易对 RocketMQ 进行扩展或者二次开发。
RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。
RocketMQ 的性能比 RabbitMQ 要高一个数量级,每秒钟大概能处理几十万条消息。
RocketMQ 的劣势是与周边生态系统的集成和兼容程度不够。
基础概念
- Producer: 消息生产者,负责产生消息,一般由业务系统负责产生消息。
- Producer Group: 消息生产者组,简单来说就是多个发送同一类消息的生产者称之为一个生产者。
- Consumer: 消息消费者,负责消费消息,一般是后台系统负责异步消费。
- Consumer Group: 消费者组,和生产者类似,消费同一类消息的多个 Consumer 实例组成一个消费者组。
- Topic: 主题,用于将消息按主题做划分,Producer将消息发往指定的Topic,Consumer订阅该Topic就可以收到这条消息。
- Message: 消息,每个message必须指定一个topic,Message 还有一个可选的 Tag 设置,以便消费端可以基于 Tag 进行过滤消息。
- Tag: 标签,子主题(二级分类)对topic的进一步细化,用于区分同一个主题下的不同业务的消息。
- Broker: Broker是RocketMQ的核心模块,负责接收并存储消息,同时提供Push/Pull接口来将消息发送给Consumer。Broker同时提供消息查询的功能,可以通过MessageID和MessageKey来查询消息。Borker会将自己的Topic配置信息实时同步到NameServer。
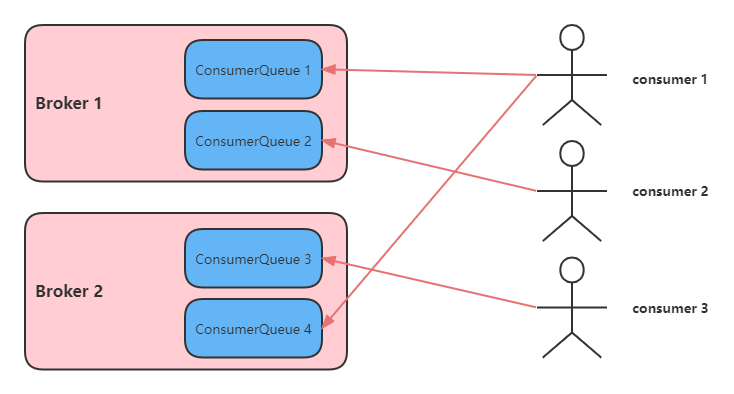
- Queue: Topic和Queue是1对多的关系,一个Topic下可以包含多个Queue,主要用于负载均衡,Queue数量设置建议不要比消费者数少。发送消息时,用户只指定Topic,Producer会根据Topic的路由信息选择具体发到哪个Queue上。Consumer订阅消息时,会根据负载均衡策略决定订阅哪些Queue的消息。
- Offset: RocketMQ在存储消息时会为每个Topic下的每个Queue生成一个消息的索引文件,每个Queue都对应一个Offset记录当前Queue中消息条数。
- NameServer: NameServer可以看作是RocketMQ的注册中心,它管理两部分数据: 集群的Topic-Queue的路由配置;Broker的实时配置信息。其它模块通过Nameserv提供的接口获取最新的Topic配置和路由信息;各 NameServer 之间不会互相通信, 各 NameServer 都有完整的路由信息,即无状态。
- Producer/Consumer : 通过查询接口获取Topic对应的Broker的地址信息和Topic-Queue的路由配置
- Broker : 注册配置信息到NameServer, 实时更新Topic信息到NameServer
RocketMQ 消费模式
广播模式
一条消息被多个Consumer消费,即使这些Consumer属于同一个Consumer Group,消息也会被Consumer Group中的每一个Consumer都消费一次。
// 设置广播模式
consumer.setMessageModel(MessageModel.BROADCASTING);集群模式
一个Consumer Group中的所有Consumer平均分摊消费消息(组内负载均衡)。
// 设置集群模式 也就是负载均衡模式
consumer.setMessageModel(MessageModel.CLUSTERING);基础架构
RocketMq 使用轻量级的NameServer服务进行服务的协调和治理工作,NameServer多节点部署时相互独立互不干扰。每一个rocketMq服务节点(broker节点)启动时都会遍历配置的NameServer列表并建立长链接,broker节点每30秒向NameServer发送一次心跳信息,NameServer每10秒会检查一次连接的broker是否存活。消费者和生产者会随机选择一个NameServer建立长连接,通过定期轮训更新的方式获取最新的服务信息。架构简图如下:

- NameServer: 启动,监听端口,等待producer,consumer,broker连接上来。
- Broker: 启动,与nameserver保持长链接,定期向nameserver发送心跳信息,包含broker的ip,端口,当前broker上topic的信息。
- producer: 启动,随机选择一个NameServer建立长连接,拿到broker的信息,然后就可以给broker发送消息了。
- consumer: 启动,随机选择一个NameServer建立长连接,拿到broker的信息,然后就可以建立通道,消费消息。
Broker 的存储结构
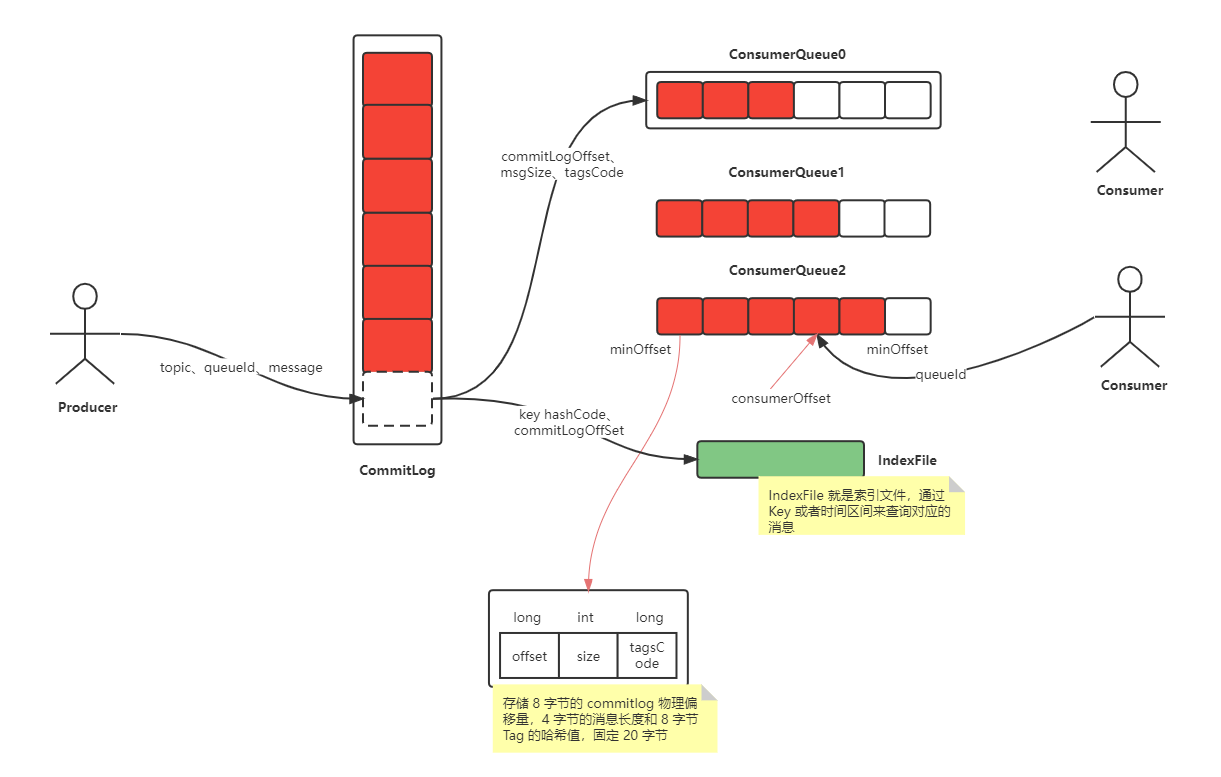
RocketMQ 存储用的是本地文件存储系统,将所有topic的消息全部写入同一个文件中(commit log),这样保证了IO写入的绝对顺序性,最大限度利用IO系统顺序读写带来的优势提升写入速度。
由于消息混合存储在一起,需要将每个消费者组消费topic最后的偏移量记录下来。这个文件就是consumer queue(索引文件)。所以消息在写入commit log 文件的同时还需将偏移量信息写入consumer queue文件。在索引文件中会记录消息的物理位置,偏移量offse,消息size等,消费者消费时根据上述信息就可以从commit log文件中快速找到消息信息。
Broker 存储结构如下:
存储文件简介
- Commit log: 消息存储文件,RocketMQ会对commit log文件进行分割(默认大小1GB),新文件以消息最后一条消息的偏移量命名。(比如 00000000000000000000 代表了第一个文件,第二个文件名就是 00000000001073741824,表明起始偏移量为 1073741824)。
- Consumer queue: 消息消费队列(也是个文件),可以根据消费者数量设置多个,一个Topic 下的某个 Queue,每个文件约 5.72M,由 30w 条数据组成;ConsumeQueue 存储的条目是固定大小,只会存储 8 字节的 commitlog 物理偏移量,4 字节的消息长度和 8 字节 Tag 的哈希值,固定 20 字节;消费者是先从 ConsumeQueue 来得到消息真实的物理地址,然后再去 CommitLog 获取消息。
- IndexFile: 索引文件,是额外提供查找消息的手段,通过 Key 或者时间区间来查询对应的消息。
整个流程简介
Producer 使用轮询的方式分别向每个 Queue 中发送消息。
Consumer 启动的时候会在 Topic,Consumer group 维度发生负载均衡,为每个客户端分配需要处理的 Queue。负载均衡过程中每个客户端都获取到全部的的 ConsumerID 和所有 Queue 并进行排序,每个客户端使用相同负责均衡算法,例如平均分配的算法,这样每个客户端都会计算出自己需要消费那些 Queue,每当 Consumer 增加或减少就会触发负载均衡,所以我们可以通过 RocketMQ 负载均衡机制实现动态扩容,提升客户端收发消息能力。客户端负责均衡为客户端分配好 Queue 后,客户端会不断向 Broker 拉取消息,在客户端进行消费。
可以一直增加客户端的数量提升消费能力吗?
当然不可以,因为 Queue 数量有限,客户端数量一旦达到 Queue 数量,再扩容新节点无法提升消费能力,因为会有节点分配不到 Queue 而无法消费。
Consumer 端的负载均衡机制
topic 在创建之处可以设置 consumer queue数量。而 consumer 在启动时会和comsumer queue绑定,这个绑定策略是咋样的?
- 默认策略:
- queue 个数大于 Consumer个数, 那么 Consumer 会平均分配 queue,不够平均,会根据clientId排序来拿取余数
- queue个数小于Consumer个数,那么会有Consumer闲置,就是浪费掉了,其余Consumer平均分配到queue
- 一致性hash算法
- 就近元则,离的近的消费
- 每个消费者依次消费一个queue,环状
- 自定义方式
天然弊端:
RocketMQ 采用一个 consumer 绑定一个或者多个 Queue 模式,假如某个消费者服务器挂了,则会造成部分Queue消息堆积。
消息刷盘机制
- 同步刷盘: 当消息持久化完成后,Broker才会返回给Producer一个ACK响应,可以保证消息的可靠性,但是性能较低。
- 异步刷盘: 只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了RocketMQ的性能和吞吐量。
Mmap + pageCache
RocketMQ 底层对 commitLog,consumeQueue 之类的磁盘文件的读写操作都采用了 mmap 技术。
传统 IO
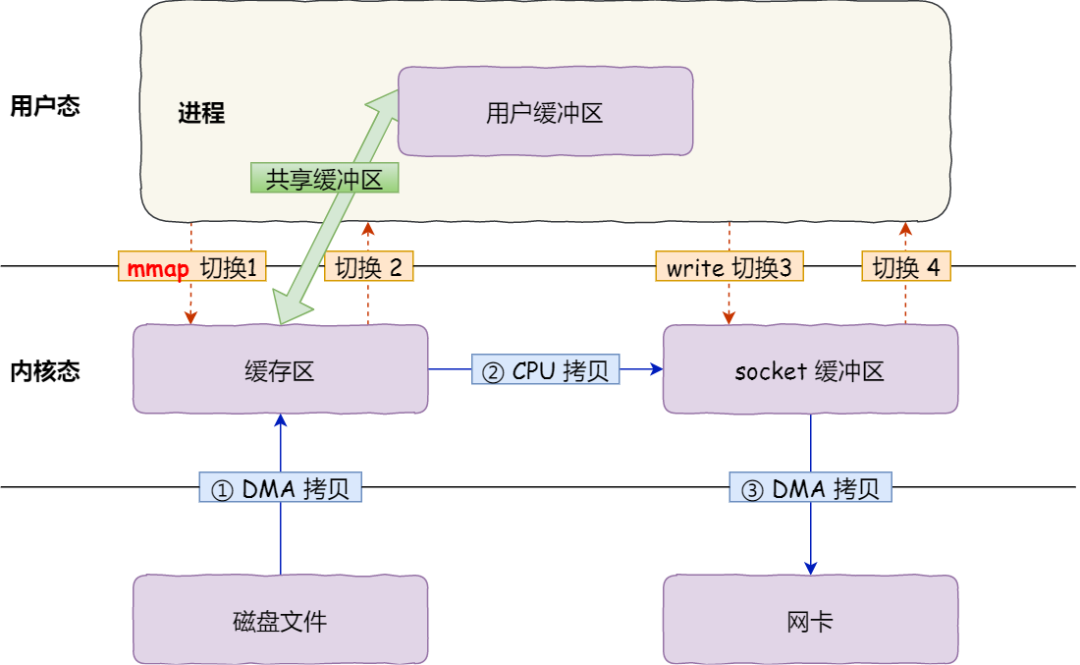
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
传统IO发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的。
传统IO,write() 过程是怎样?
write() 写请求 和 read(),需要先写入用户缓存区,然后通过系统调用,CPU 拷贝数据从用户缓存区到内核缓存区,再从内核缓存区拷贝到磁盘文件!
- 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
- 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的(用户态不能直接操作内核态缓存区,所以需要拷贝到用户态才能使用)。
- 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
- 第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
如何优化文件传输的性能? 先来看看,如何减少「用户态与内核态的上下文切换」的次数呢?
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换: 首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
再来看看,如何减少「数据拷贝」的次数?
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
Mmap(内存映射)
read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
mmap() 系统调用函数会把文件磁盘地址「映射」到内核缓存区(page cache),而内核缓存区会 「映射」到用户空间(虚拟地址)。这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝。
注意,这里用户空间(虚拟地址)不是直接映射到文件磁盘地址,而是文件对应的 page cache,用户虚拟地址一般是和用户内存地址「映射」的,如果使用内存映射技术,则用户虚拟地址可以和内核内存地址「映射」。
根据维基百科给出的定义: 在大多数操作系统中,映射的内存区域实际上是内核的page cache,这意味着不需要在用户空间创建副本。多个进程之间也可以通过同时映射 page cache,来进行进程通信)
mmap() 函数简介
void * mmap(void *start, size_t length, int prot , int flags, int fd, off_t offset)- start: 要映射到的内存区域的起始地址,通常都是用NULL(NULL即为0)。NULL表示由内核来指定该内存地址
- offset: 以文件开始处的偏移量, 必须是分页大小的整数倍, 通常为0, 表示从文件头开始映射
- length: 将文件的多大长度映射到内存(每次创建新 commitlog 会默认指定长度 1GB)
- prot: 映射区的保护方式(PROT_EXEC: 映射区可被执行,PROT_READ: 映射区可被读取,PROT_WRITE: 映射区可被写入,PROT_NONE: 映射区不能存取)
- flags: 映射区的特性
- fd: 文件描述符(由open函数返回)
从磁盘拷贝到内核空间的页缓存 (page cache),然后将用户空间的虚拟地址映射到内核的page cache,这样不需要再将页面从内核空间拷贝到用户空间了。
简述上述过程
- 应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区;
- 应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
- 应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
- 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
使用 mmap() 写数据到磁盘文件会怎样?
mmap() 将用户虚拟地址映射内核缓存区(内存物理地址)后,写数据直接将数据写入内核缓存区,只需要经过一次CPU拷贝,将数据从内核缓存区拷贝到磁盘文件;比传统 IO 的 write() 操作少了一次数据拷贝的过程!
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
pageCache
在传统IO过程中,其中第一步都是先需要先把磁盘文件数据拷贝「内核缓冲区」里,这个「内核缓冲区」实际上是磁盘高速缓存(PageCache)。
预映射机制 + 文件预热机制
Broker针对上述的磁盘文件高性能读写机制做的一些优化:
-
内存预映射机制: Broker 会针对磁盘上的各种 CommitLog,ConsumeQueue 文件预先分配好MappedFile,也就是提前对一些可能接下来要读写的磁盘文件,提前使用 MappedByteBuffer 执行 mmap() 函数完成内存映射,这样后续读写文件的时候,就可以直接执行了(减少一次 CPU 拷贝)。
-
文件预热: 在提前对一些文件完成内存映射之后,因为内存映射不会直接将数据从磁盘加载到内存里来,那么后续在读,取尤其是 CommitLog,ConsumeQueue 文件时候,其实有可能会频繁的从磁盘里加载数据到内存中去。所以,在执行完 mmap() 函数之后,还会进行 madvise() 系统调用,就是提前尽可能将磁盘文件加载到内存里去。(读磁盘 -> 读内存)。
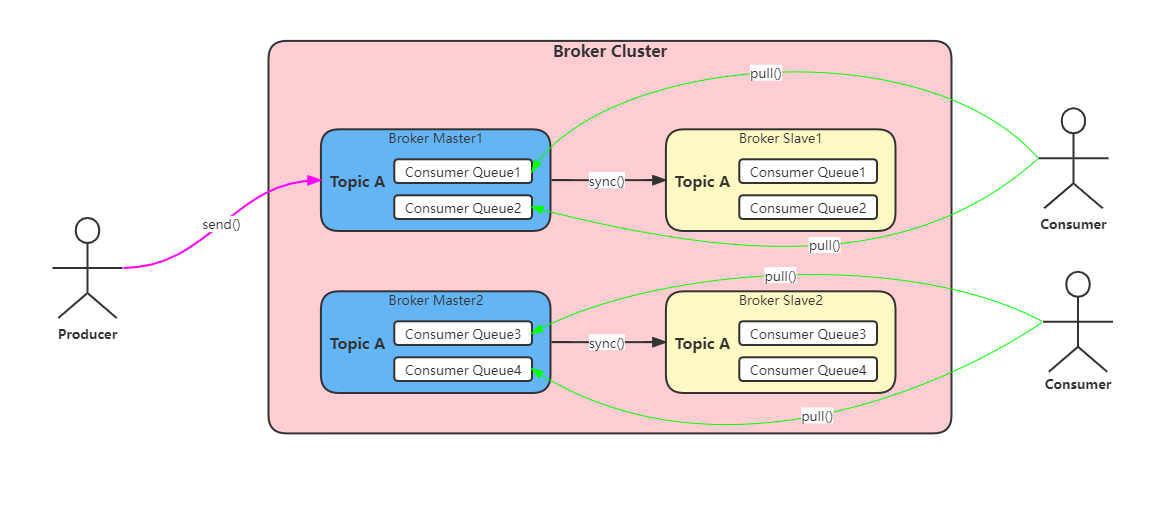
Topic 分片
为了突破单个机器容量上限和单个机器读写性能,RocketMQ 支持 topic 数据分片。
架构图如下:
查缺补漏
消息的全局顺序和局部顺序
- 全局顺序: 一个 Topic 一个队列,Producer 和 Consumer 的并发都为一。
- 局部顺序: 某个队列消息是顺序的。
零拷贝(Zero-copy)
sendfile:
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
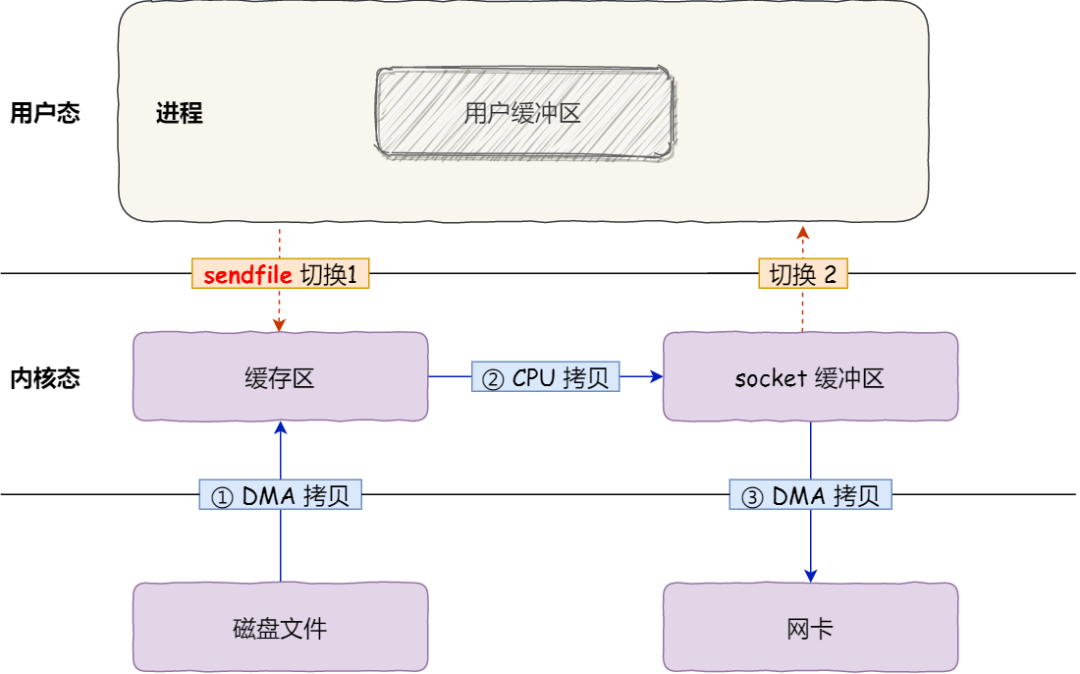
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
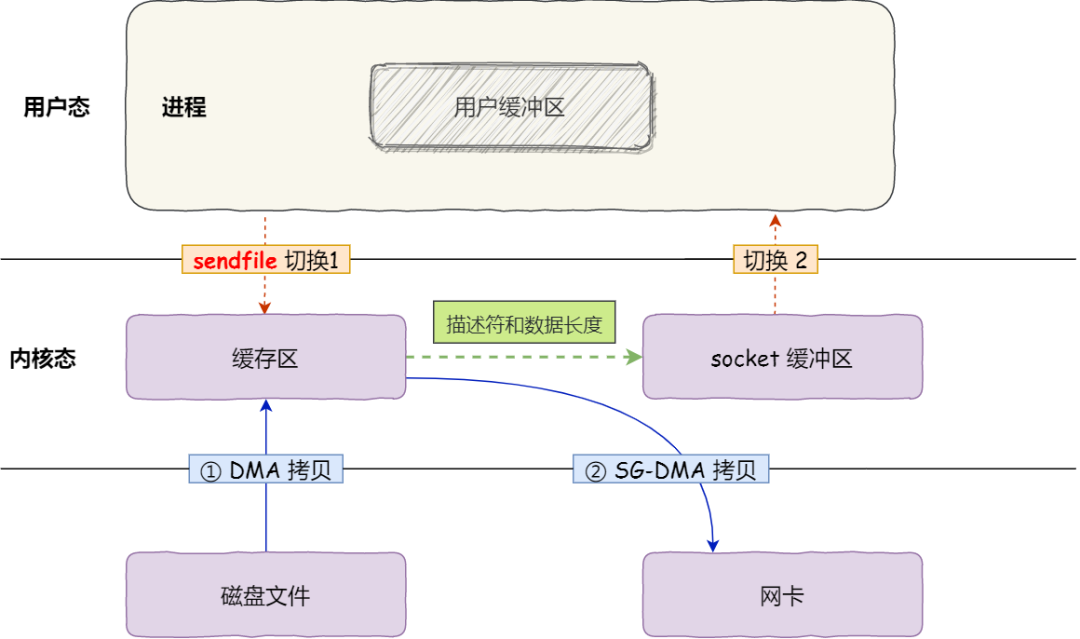
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
使用零拷贝技术的项目
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
另外,Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...
sendfile on
...
}sendfile 配置的具体意思:
- 设置为 on 表示,使用零拷贝技术来传输文件: sendfile ,这样只需要 2 次上下文切换,和 2 次数据拷贝。
- 设置为 off 表示,使用传统的文件传输技术: read + write,这时就需要 4 次上下文切换,和 4 次数据拷贝。
当然,要使用 sendfile,Linux 内核版本必须要 2.1 以上的版本。
PageCache 有什么作用?
回顾前面说道文件传输过程,其中第一步都是先需要先把磁盘文件数据拷贝「内核缓冲区」里,这个「内核缓冲区」实际上是磁盘高速缓存(PageCache)。
由于零拷贝使用了 PageCache 技术,可以使得零拷贝进一步提升了性能,我们接下来看看 PageCache 是如何做到这一点的。
读写磁盘相比读写内存的速度慢太多了,所以我们应该想办法把「读写磁盘」替换成「读写内存」。于是,我们会通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。
那问题来了,选择哪些磁盘数据拷贝到内存呢?
我们都知道程序运行的时候,具有「局部性」,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。
所以,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。
另外,由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
- PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
- PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次;
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,这样在高并发的环境下,会带来严重的性能问题。
大文件传输用什么方式实现?
那针对大文件的传输,我们应该使用什么方式呢?
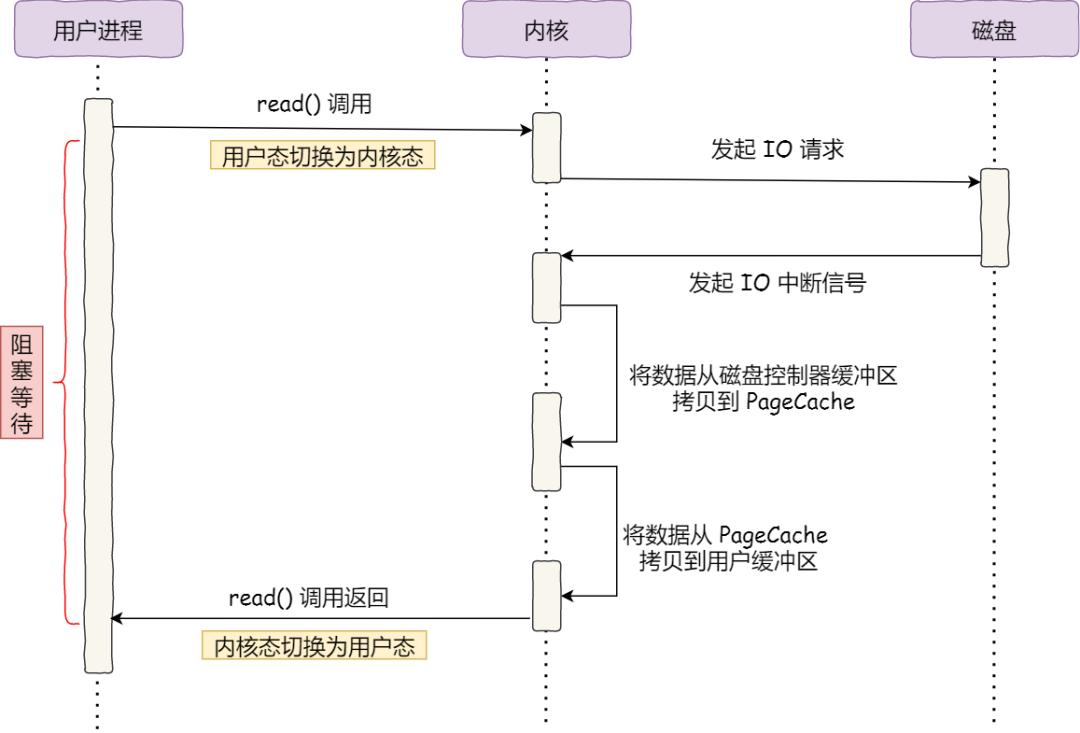
我们先来看看最初的例子,当调用 read 方法读取文件时,进程实际上会阻塞在 read 方法调用,因为要等待磁盘数据的返回,如下图:
具体过程:
- 当调用 read 方法时,会阻塞着,此时内核会向磁盘发起 I/O 请求,磁盘收到请求后,便会寻址,当磁盘数据准备好后,就会向内核发起 I/O 中断,告知内核磁盘数据已经准备好;
- 内核收到 I/O 中断后,就将数据从磁盘控制器缓冲区拷贝到 PageCache 里;
- 最后,内核再把 PageCache 中的数据拷贝到用户缓冲区,于是 read 调用就正常返回了。
对于阻塞的问题,可以用异步 I/O 来解决,它工作方式如下图:
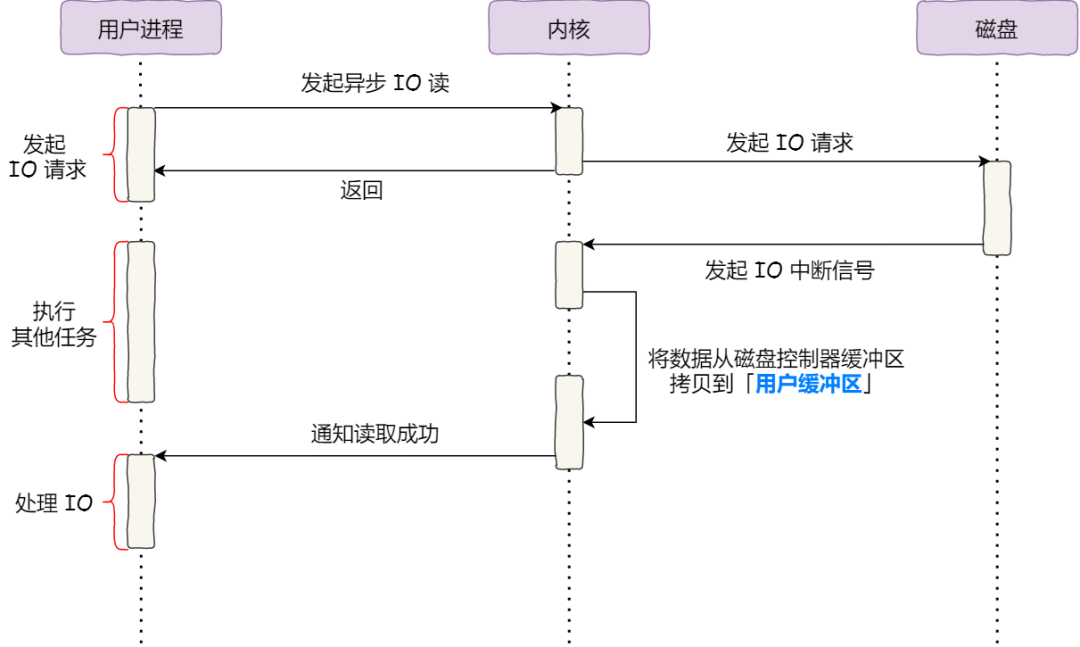
它把读操作分为两部分:
- 前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其他任务;
- 后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache,所以使用异步 I/O 就意味着要绕开 PageCache。
绕开 PageCache 的 I/O 叫直接 I/O,使用 PageCache 的 I/O 则叫缓存 I/O。通常,对于磁盘,异步 I/O 只支持直接 I/O。
前面也提到,大文件的传输不应该使用 PageCache,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache。
于是,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
直接 I/O 应用场景常见的两种:
- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
- 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。
另外,由于直接 I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
- 内核也会「预读」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
于是,传输大文件的时候,使用「异步 I/O + 直接 I/O」了,就可以无阻塞地读取文件了。
所以,传输文件的时候,我们要根据文件的大小来使用不同的方式:
- 传输大文件的时候,使用「异步 I/O + 直接 I/O」;
- 传输小文件的时候,则使用「零拷贝技术」;
在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}当文件大小大于 directio 值后,使用「异步 I/O + 直接 I/O」,否则使用「零拷贝技术」。
总结
早期 I/O 操作,内存与磁盘的数据传输的工作都是由 CPU 完成的,而此时 CPU 不能执行其他任务,会特别浪费 CPU 资源。
于是,为了解决这一问题,DMA 技术就出现了,每个 I/O 设备都有自己的 DMA 控制器,通过这个 DMA 控制器,CPU 只需要告诉 DMA 控制器,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。后续的实际数据传输工作,都会由 DMA 控制器来完成,CPU 不需要参与数据传输的工作。
传统 IO 的工作方式,从硬盘读取数据,然后再通过网卡向外发送,我们需要进行 4 上下文切换,和 4 次数据拷贝,其中 2 次数据拷贝发生在内存里的缓冲区和对应的硬件设备之间,这个是由 DMA 完成,另外 2 次则发生在内核态和用户态之间,这个数据搬移工作是由 CPU 完成的。
为了提高文件传输的性能,于是就出现了零拷贝技术,它通过一次系统调用(sendfile 方法)合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。另外,拷贝数据都是发生在内核中的,天然就降低了数据拷贝的次数。
Kafka 和 Nginx 都有实现零拷贝技术,这将大大提高文件传输的性能。
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 IO 合并与预读,这也是顺序读比随机读性能好的原因。这些优势,进一步提升了零拷贝的性能。
需要注意的是,零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送。
另外,当传输大文件时,不能使用零拷贝,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,并且大文件的缓存命中率不高,这时就需要使用「异步 IO + 直接 IO 」的方式。
在 Nginx 里,可以通过配置,设定一个文件大小阈值,针对大文件使用异步 IO 和直接 IO,而对小文件使用零拷贝。
Kafka为什么那么快?
- 顺序读写+mmap,使用linux内核提供的mmap api,mmap将磁盘文件(设备内存)映射到内存,支持读和写,对内存的操作就会反映在磁盘文件上,但这不是实时写入磁盘的,操作系统会在程序主动调用flush的时候才真正的把数据写到硬盘(kafka也提供了一个参数——producer.type来控制是不是主动flush,如果kafaka写入到mmap之后立即flush然后返回producer叫同步,写入mmap之后立即返回producer叫异步)。
- 零拷贝,使用linux内核提供的sendfile api,sendfile是将读到内核空间的数据,直接转到socket buffer,进行网络发送。
什么是mmap?
mmap是操作这些设备的一种方法,所谓操作设备,比如IO端口(点亮一个LED),LCD控制器,磁盘控制器,实际上就是往设备的物理地址读写数据。
但是,由于应用程序不能直接操作设备硬件地址,所以操作系统提供了这样的一种机制——内存映射,把设备地址映射到进程虚拟地址,mmap就是实现内存映射的接口。
mmap的好处是,mmap把设备内存映射到虚拟内存,则用户操作虚拟内存相当于直接操作设备了,省去了用户空间到内核空间的复制过程,相对IO操作来说,增加了数据的吞吐量。
什么是内存映射?
既然mmap是实现内存映射的接口,那么内存映射是什么呢?看下图:
每个进程都有独立的进程地址空间,通过页表和MMU,可将虚拟地址转换为物理地址,每个进程都有独立的页表数据,这可解释为什么两个不同进程相同的虚拟地址,却对应不同的物理地址。
什么是虚拟地址空间?
每个进程都有4G的虚拟地址空间,其中3G用户空间,1G内核空间(linux),每个进程共享内核空间,独立的用户空间,下图形象地表达了这点
驱动程序运行在内核空间,所以驱动程序是面向所有进程的。
用户空间切换到内核空间有两种方法:
(1)系统调用,即软中断
(2)硬件中断
虚拟地址空间里面是什么?
了解了什么是虚拟地址空间,那么虚拟地址空间里面装的是什么?看下图
虚拟空间装的大概是上面那些数据了,内存映射大概就是把设备地址映射到上图的红色段了,暂且称其为”内存映射段”,至于映射到哪个地址,是由操作系统分配的,操作系统会把进程空间划分为三个部分:
(1)未分配的,即进程还未使用的地址
(2)缓存的,缓存在ram中的页
(3)未缓存的,没有缓存在ram中
操作系统会在未分配的地址空间分配一段虚拟地址,用来和设备地址建立映射。
页缓存是linux内核一种重要的磁盘高速缓存,它通过软件机制实现。但页缓存和硬件cache的原理基本相同,将容量大而低速设备中的部分数据存放到容量小而快速的设备中,这样速度快的设备将作为低速设备的缓存,当访问低速设备中的数据时,可以直接从缓存中获取数据而不需再访问低速设备,从而节省了整体的访问时间。
页缓存以页为大小进行数据缓存,它将磁盘中最常用和最重要的数据存放到部分物理内存中,使得系统访问块设备时可以直接从主存中获取块设备数据,而不需从磁盘中获取数据。
在大多数情况下,内核在读写磁盘时都会使用页缓存。内核在读文件时,首先在已有的页缓存中查找所读取的数据是否已经存在。如果该页缓存不存在,则一个新的页将被添加到高速缓存中,然后用从磁盘读取的数据填充它。如果当前物理内存足够空闲,那么该页将长期保留在高速缓存中,使得其他进程再使用该页中的数据时不再访问磁盘。写操作与读操作时类似,直接在页缓存中修改数据,但是页缓存中修改的数据(该页此时被称为Dirty Page)并不是马上就被写入磁盘,而是延迟几秒钟,以防止进程对该页缓存中的数据再次修改。